- LLMs are the engine, not the car: A Large Language Model provides raw reasoning and text-generation power, but it operates in isolation without an orchestrator.
- CrewAI is the management layer: It transforms standalone LLMs into a structured multi-agent workforce where specialized agents delegate tasks, use tools, and collaborate.
- Context is limited; systems scale: Relying on a single LLM prompt for complex workflows leads to context degradation. CrewAI solves this through role-based task decomposition.
Introduction
For the past two years, Large Language Models (LLMs) have dominated the tech landscape. But as engineering teams move from building proof-of-concept chatbots to production-grade data pipelines, a harsh reality sets in: a single LLM, no matter how large its context window, struggles with complex, multi-step workflows.
If you ask a raw LLM to "research a competitor, analyze their financials, and write a Python script to scrape their pricing," it will likely fail halfway through, drop constraints, or hallucinate entirely. This is where multi-agent orchestration frameworks like CrewAI step in. This post breaks down the core differences between a standalone LLM and a CrewAI-orchestrated system, and explains why the future of enterprise GenAI is agentic.
The Concept & The Problem: The Limits of a Single Prompt
An LLM on its own is essentially a highly sophisticated text predictor. It takes an input, predicts the most likely next tokens, and stops. When building enterprise tools, relying solely on this single-prompt architecture presents major roadblocks:
- Context Degradation: Piling too many instructions, schemas, and requirements into one massive prompt causes the model to "forget" the middle steps or lose focus on the primary goal.
- Lack of Tool Synergy: While you can give an LLM a tool (like a web searcher or a SQL executor), managing when and how it uses 10 different tools simultaneously gets messy and inflates token costs.
- No Division of Labor: You are asking the same neural network to be a researcher, a data engineer, and a QA tester all at once, using the same context window.
To bridge the gap between raw LLM capabilities and actual task execution, the LLM must be wrapped in an agentic loop — a framework that provides memory, planning, and observation steps.
Key insight: An AI agent is simply an LLM equipped with a systemic loop for memory, observation, and tool execution.
In-Depth Comparison: LLM vs. CrewAI
Let's take a deep dive into how a raw LLM approach compares to a CrewAI setup across three critical dimensions: Architecture, Delegation, and Tool Assignment. This illustrates the shift from single-node processing to a distributed workforce model.
1. Architecture: Single Node vs. Multi-Agent Organization
Standalone LLM: Operates as a single, sequential pipeline. You send a prompt, and the model processes it linearly. If a reasoning error occurs at step 2 of a 5-step process, the entire final output is flawed because the LLM lacks an isolated peer-review mechanism.
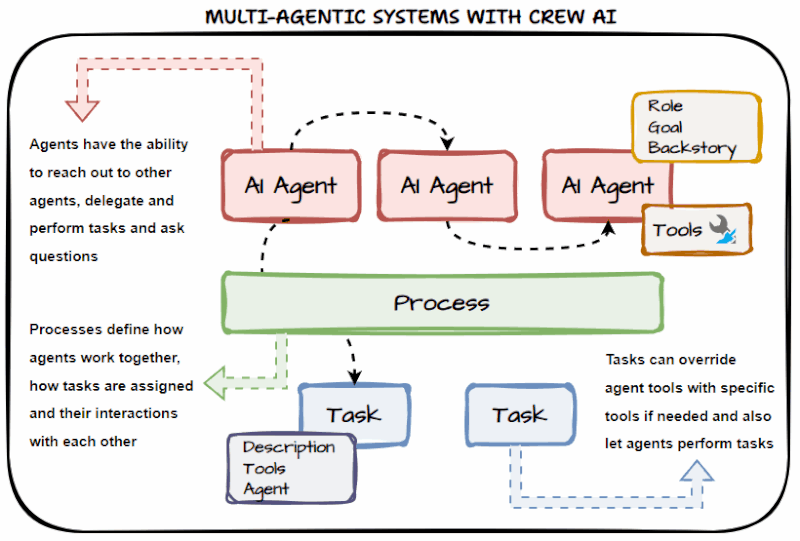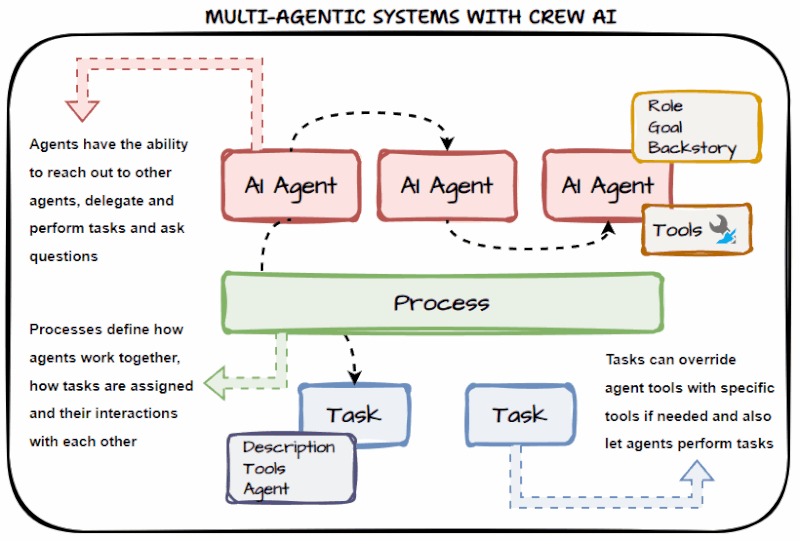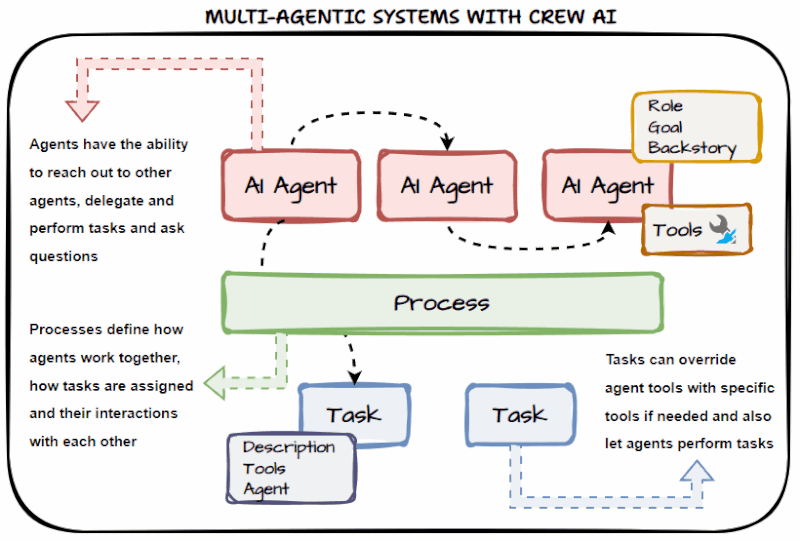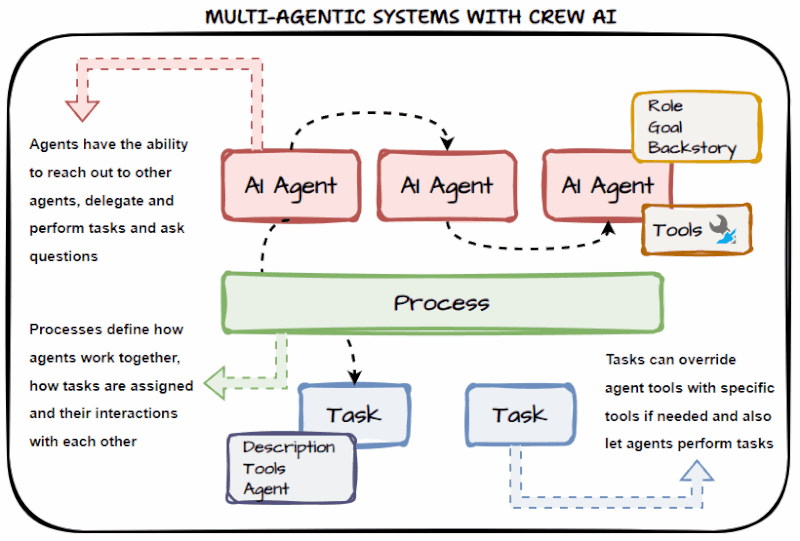
CrewAI: Designed around the concept of a human workforce. You define individual Agents with specific Roles, Goals, and Backstories. These agents operate in sequence or hierarchically, passing verified, isolated outputs to one another. The architecture fundamentally shifts from prompting a black box to managing a digital team.
2. Task Delegation and Memory Management
Standalone LLM: Relies entirely on the developer to write complex application code to manage conversational memory, parse outputs, chunk data, and feed it back into the model for the next step. It is highly brittle.
CrewAI: Features built-in delegation capabilities. If the "Lead Developer Agent" needs a specific Python ingestion script tested, it can autonomously delegate that sub-task to the "QA Agent" and wait for the verified result before returning the final output to the user. Memory is segregated by agent role, keeping context windows lean and relevant.
3. Tool Assignment and Metadata-Driven Execution
Standalone LLM: When you bind too many tools (search, scrape, API calls) to a single LLM, the model struggles to decide which one to use. This leads to higher latency, frequent hallucinations, and "tool looping" where the LLM repeatedly calls the wrong function.
CrewAI: Tools are bound at the Agent level, not the system level. Your "Web Scraping Agent" only has access to a web scraper, and your "Database Agent" only has access to your data warehouse connector. Limiting an agent's toolset forces it to stay in its lane, drastically improving execution accuracy and reducing operational costs.
This site runs on the exact CrewAI stack described above. Our 9-agent C-suite (CEO, CMO, CPO, CTO, CFO, Content, Social, PM, Ops) operates as a sequential crew — each agent receives a task, uses only its assigned tools, and passes verified output to the next. The weekly board report you read is literally the crew's final artifact. See the architecture →
Conclusion
Comparing an LLM to CrewAI is like comparing a brilliant individual contributor to a well-structured department. The LLM provides the raw cognitive power, but CrewAI provides the organizational structure, accountability, and workflow required to get actual work done reliably. As we build more robust, metadata-driven applications, moving our mindset from "prompt engineering" to "multi-agent orchestration" is the necessary next step for scalable AI.
Leading technical strategy and architecting next-generation AI pipelines. Passionate about multi-agent orchestration, scaling large language models for enterprise utility, and transforming complex workflows into automated, intelligent systems.
- CrewAI Official Documentation — Core concepts on Agents, Tasks, and Crews.
- The Anatomy of an AI Agent (Lilian Weng) — A foundational paper on how LLMs power agentic workflows.
- DeepLearning.AI: Multi AI Agent Systems with crewAI — Practical courses on building orchestrated systems.